2024-09-03: ETL Jobs filled the analyticsdb
Date
2024-09-07 09:00 WEST
Summary
- AnalyticsDB started to fill up with a huge amount of data. Went from 10GB used to 760GB in 4h.
- Why ?
- ETL SQL batch jobs seem to produce too many results
- Why ?
- A SQL query was producing too many rows
Authors
@zaibon
Impact
The information about the impact of the issue including:
- affected infrastructure elements
- analyticsdb disk size grew from 10GB to 670GB
- affected product features
- All webapp feature depends on the data produced by the ETL pipelines.
- affected users
- This incident was limited to QA environment. No customers were affected.
Root Cause
The cause is 2 folds:
- The SQL used to create the repo_commit_digest data-product had a bug that made it generate multiples millions of rows instead of thousands or rows.
- The scheduling system used (dataflow + cron scheduler) to run those queries did not allow to ensure only one instance of this query ever run at the same time.
The combination of these two fact created a cascade effect on the database forcing it to create too many temporary files that eventually filled all the disks of the database instance.
Trigger
Some new version of the ETL pipeline were deployed on Friday 06 September 2024. The incident started to appear nearly immediately after all the ETL jobs were started. Around 19:00 WEST on the 06 September 2024.
Detection
- On 07 September 2024 06:30 WEST @prog8 detected a huge rise in the size of the analyticsDB.
Screenshot of the database system graphs at the time of the incident.
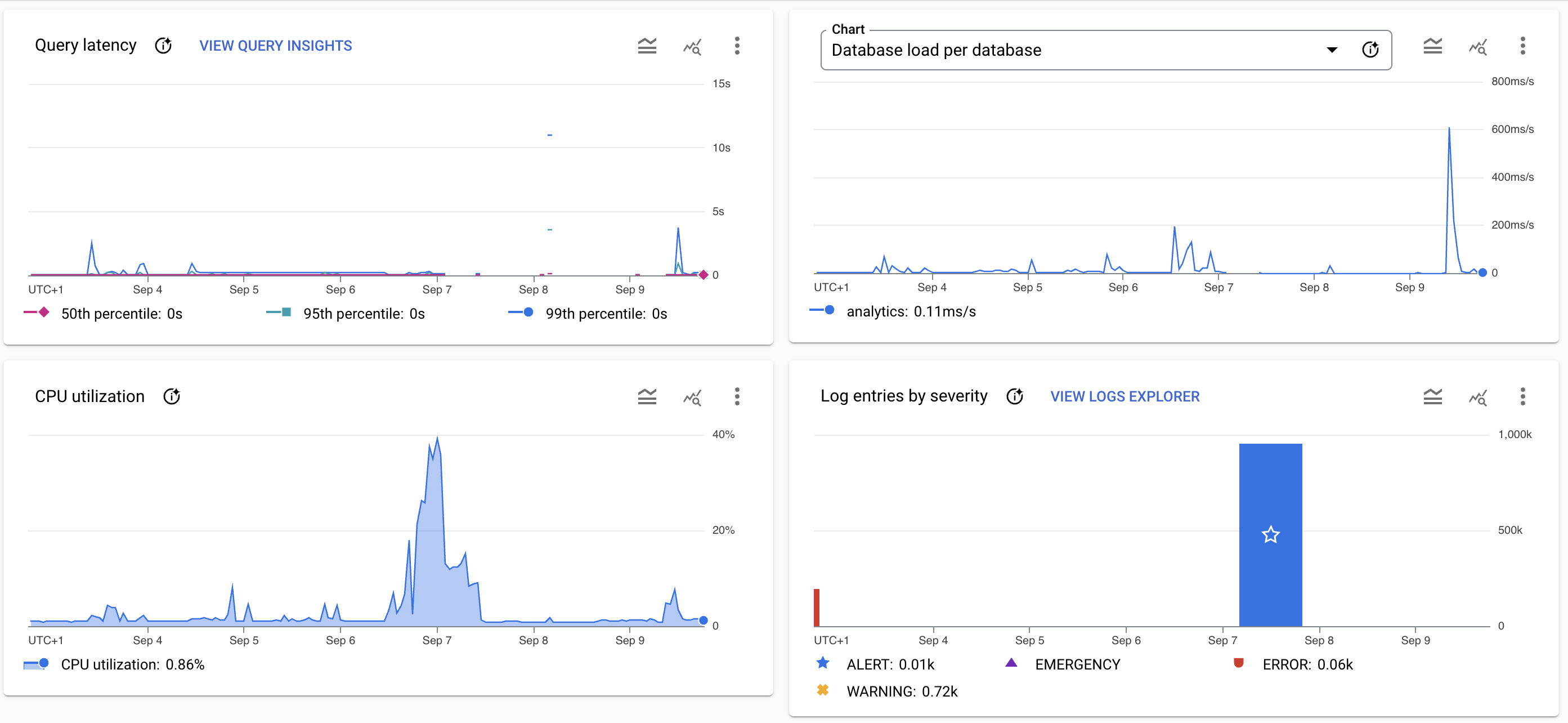
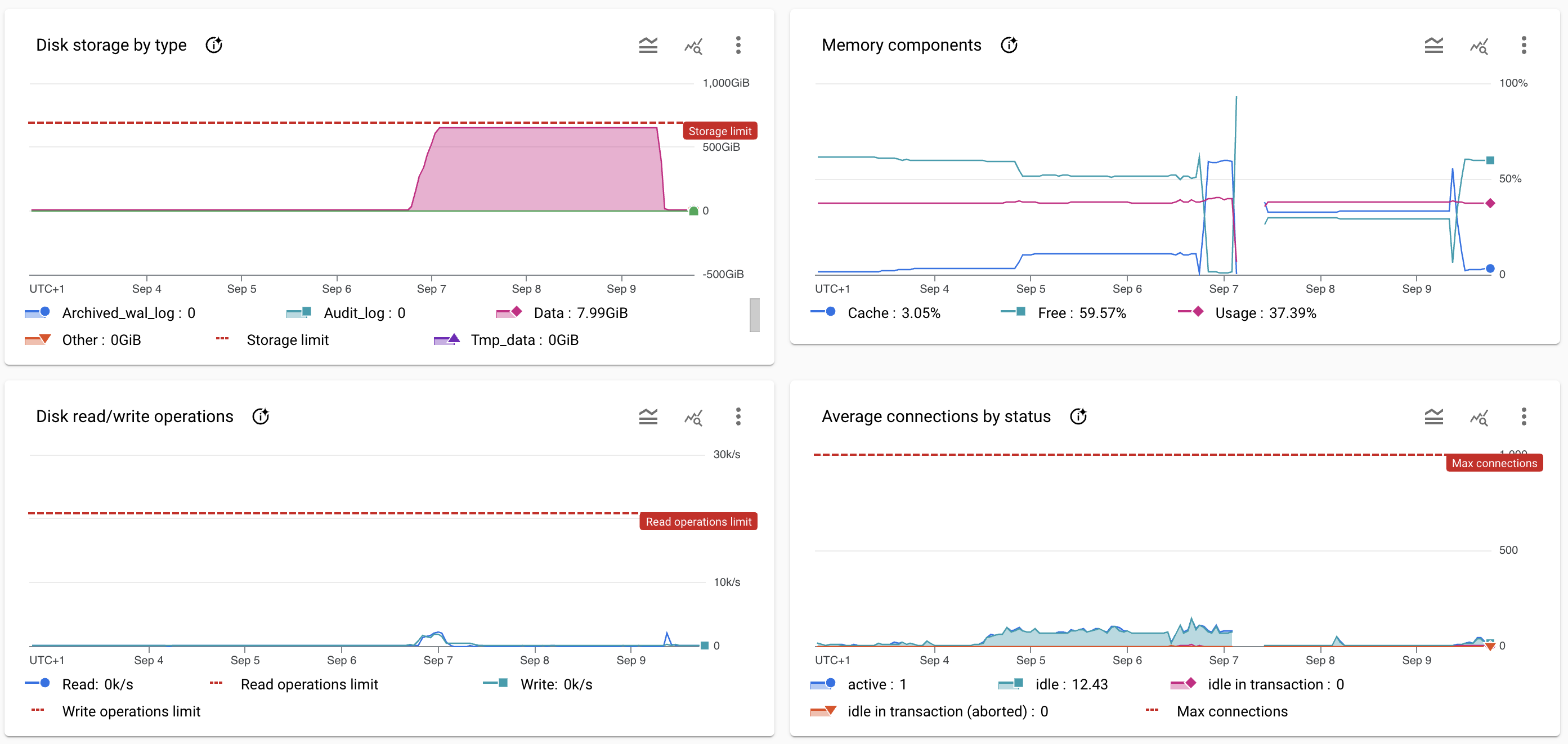
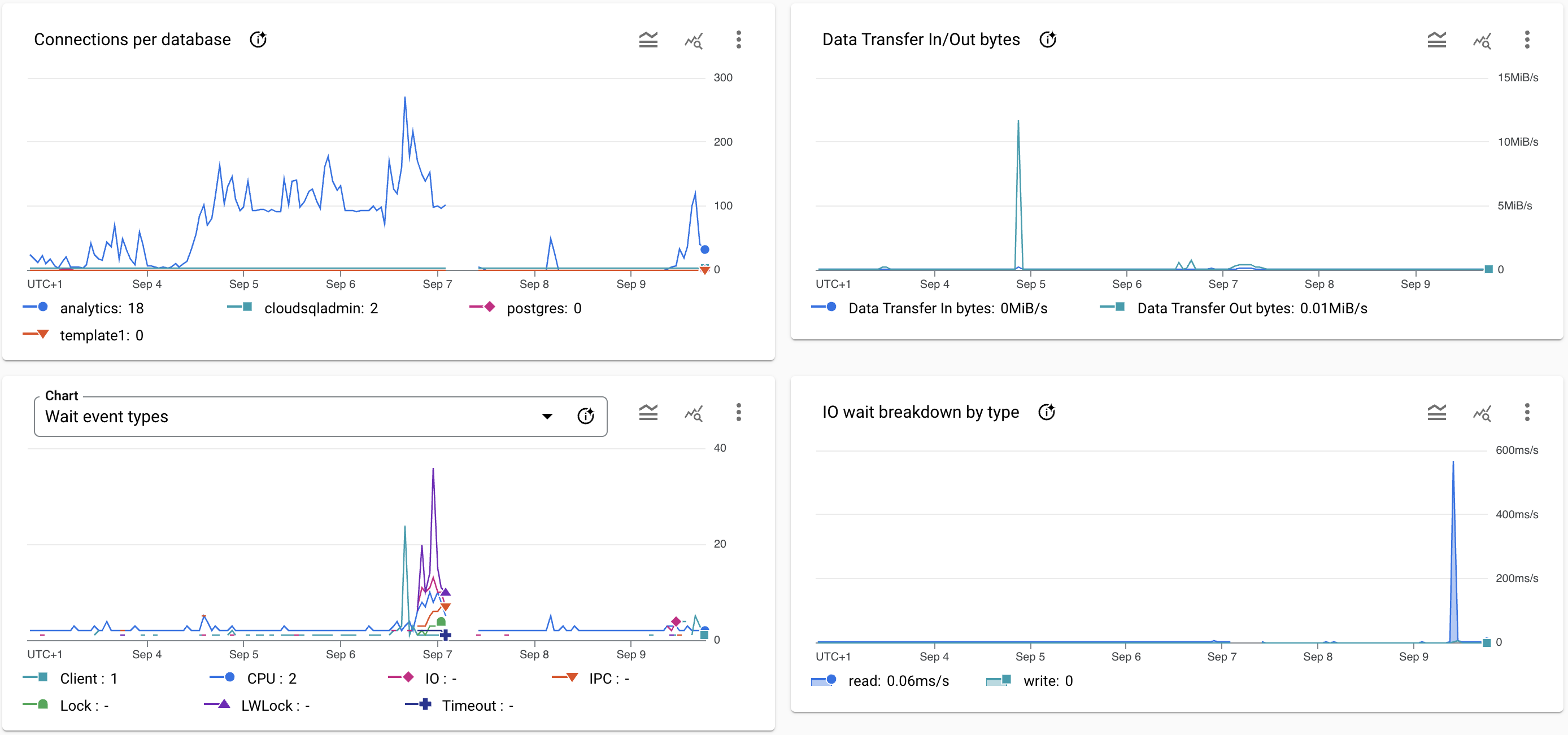
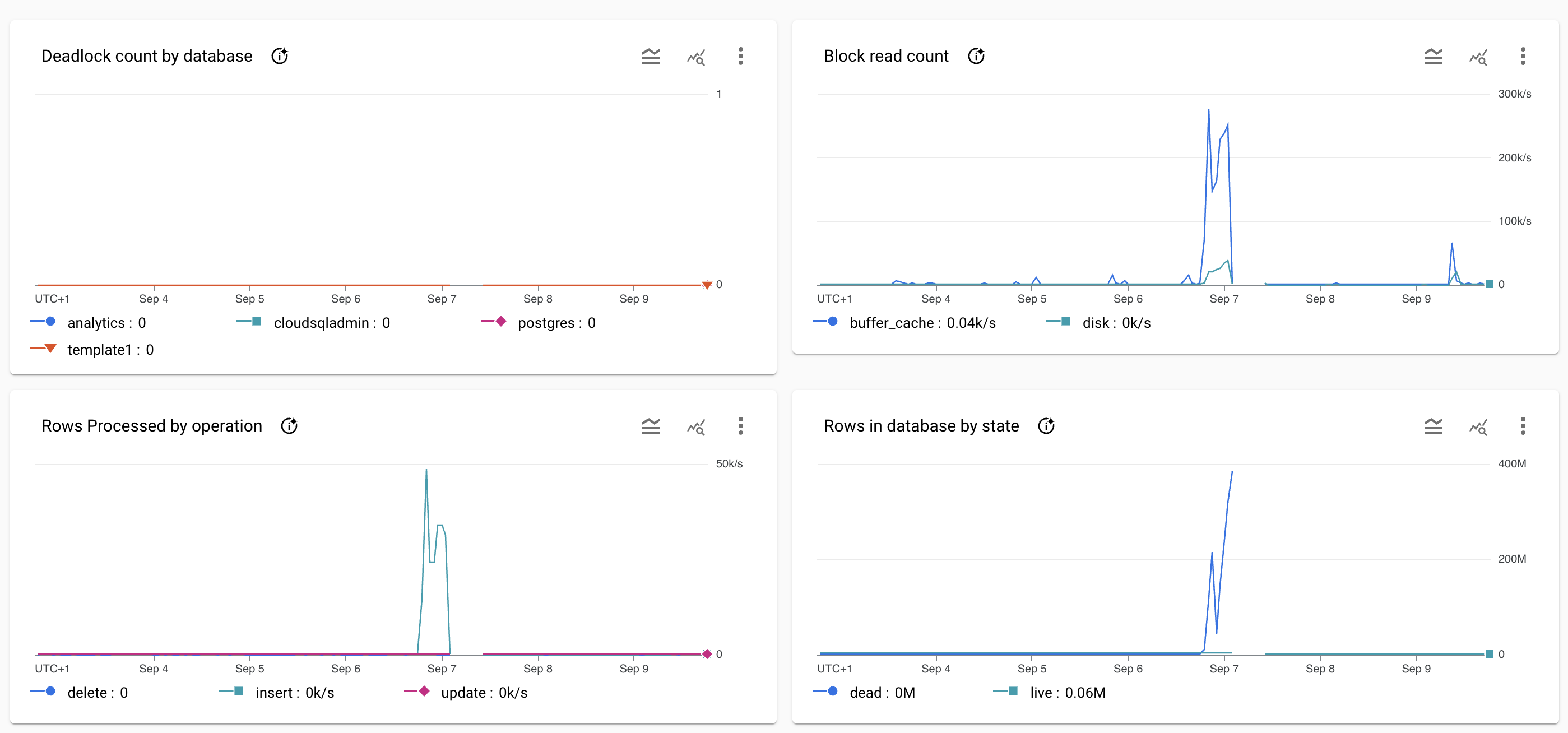
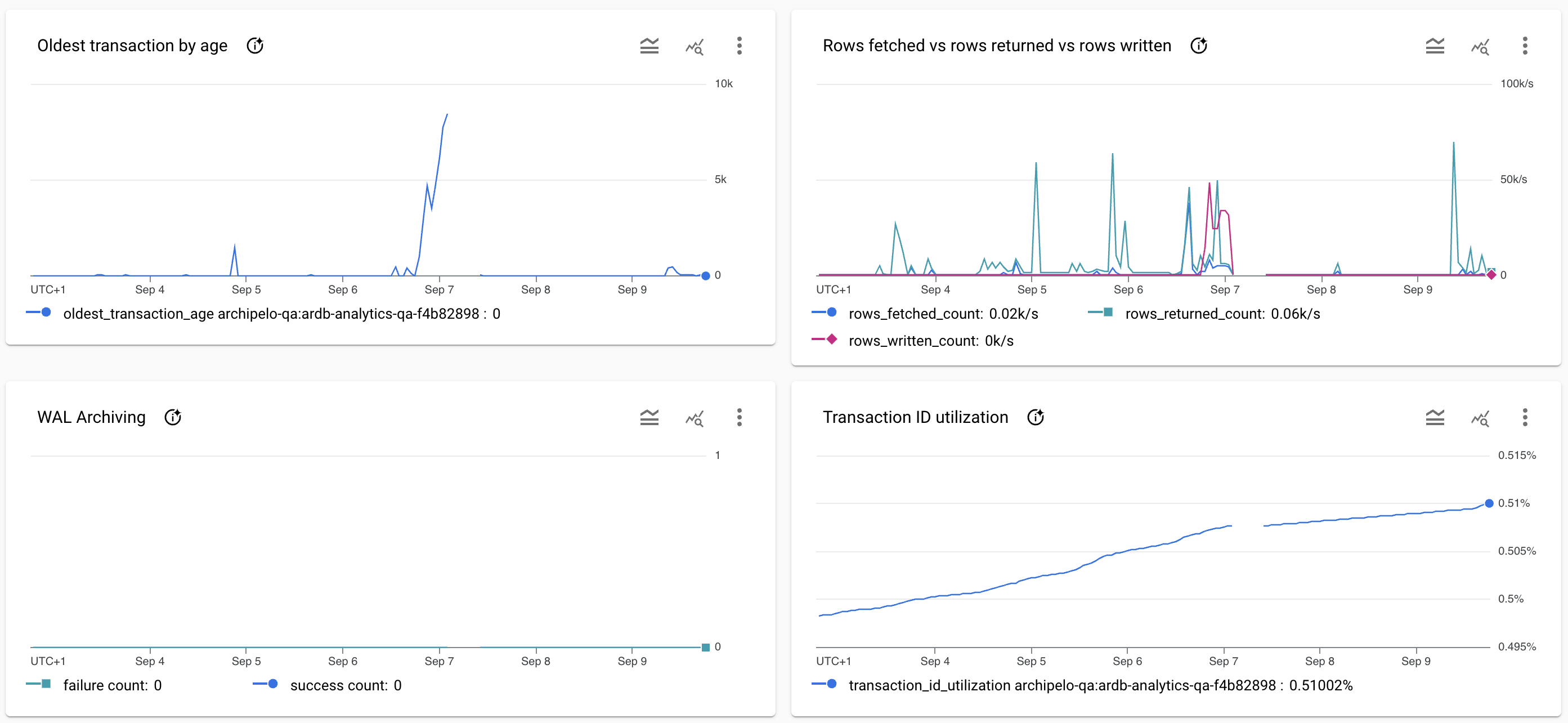
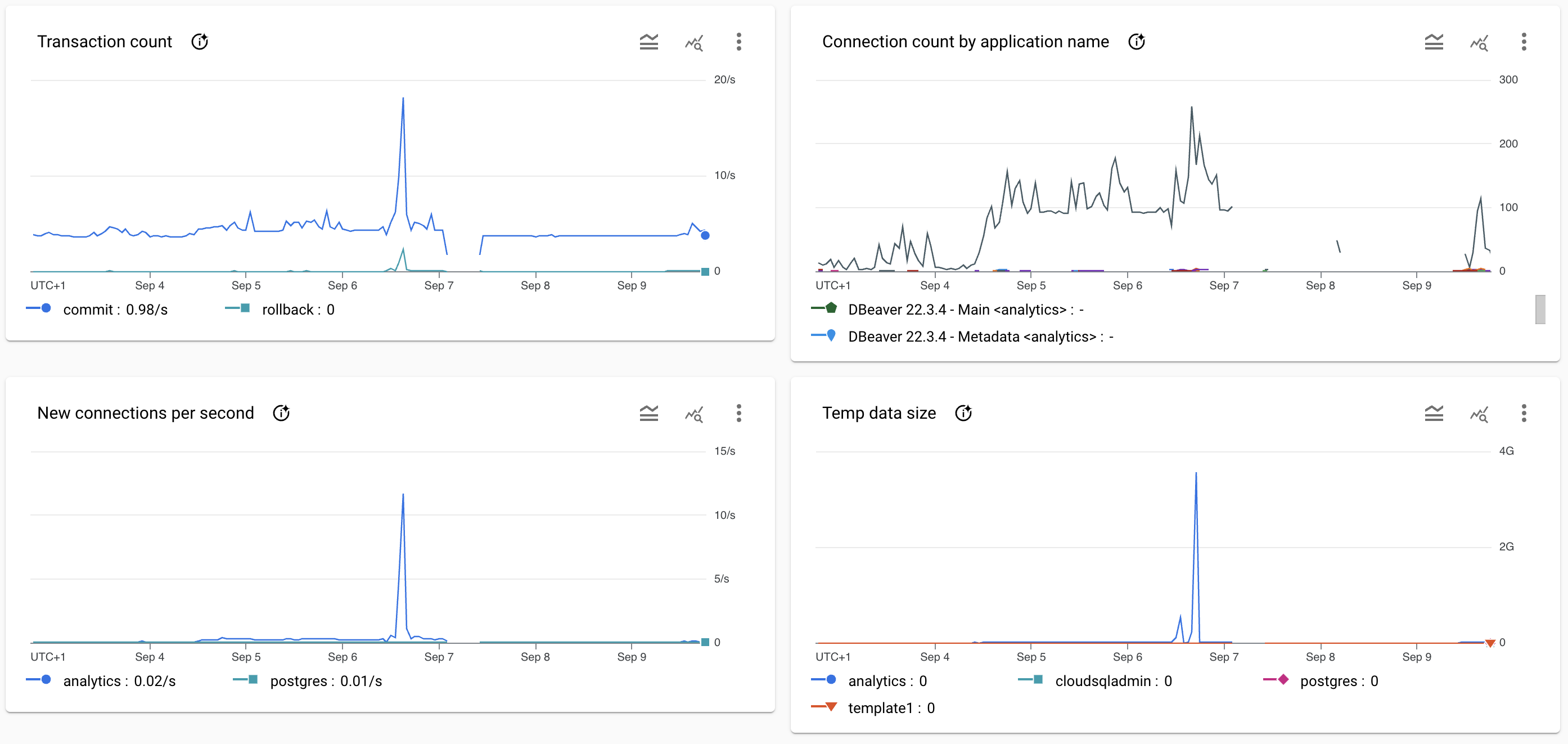
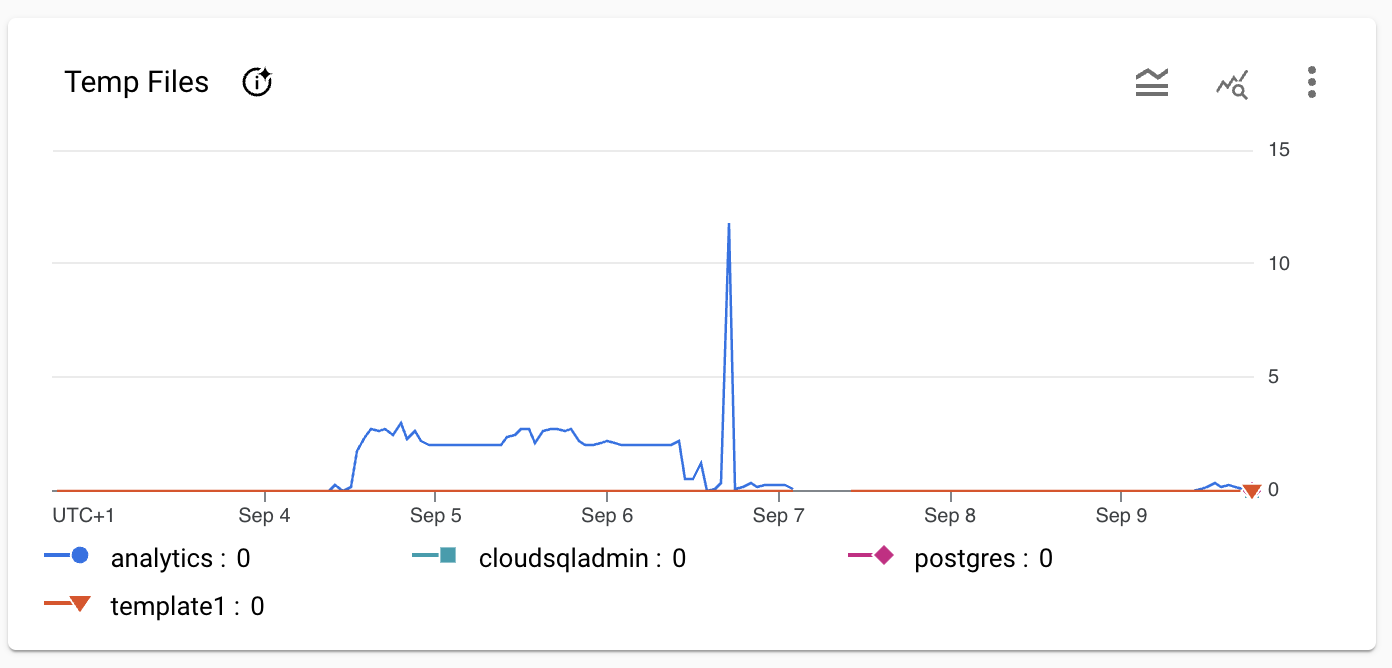
Resolution
The final resolution resolution is still in progress.
- Extracting all the SQL queries running in dataflow out.
- Building a new tool that allows us to execute SQL queries simply
Timeline
The timeline of the events related to the issue in form of the table:
- 2024-09-7 9:00AM WEST: @zaibon increase the disk size of the database to 670GB
- 9h33: max size and size increase to 670, connection possible again
| Time | Description |
|---|---|
| 2022-09-07 06:30:00 WEST | @prog detect the size of the database increased out of control |
| 2022-09-07 06:43:00 WEST | @prog stops all the ETL jobs writing to the database |
| 2022-09-07 09:00:00 WEST | @zaibon increase the database disk size of the database to 700GB to allow the database to recover |
| 2022-09-07 09:33:00 WEST | database has increased disk size and the connection to the database is possible again |
Action Items (optional)
The follow-up items for the issue with GitHub issues linked.
Retrospective (optional)
The section on the retrospective related to the issue.
Lessons Learned (optional)
- Do not push code on Friday and before the author goes on holiday
- We need better testing practices before merging code
What went well (optional)
- We got slack alert of the increase in size of the database
- Team managed to stop the increase of the database size in a timely manner